卷积神经网络通常需要大规模的标记数据,然而创建一个大规模的标记数据往往费时耗力。当标记数据有限的情况下,半监督学习的方法试图使用未标记数据来训练模型以提高模型的分类性能。
论文1
ICIP‘15《Mutual Exclusivity Loss for Semi-Supervised Deep Learning》
这篇论文提出了一个无监督的正则项,它迫使分类器为多个类别的预测相互排斥,有效的指导决策边界落在不同类别数据对应的低密度流行之间。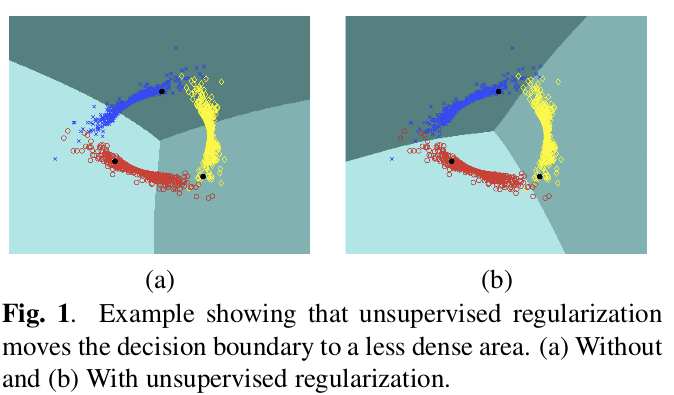
loss 函数由两部分构成(L_L+L_U),在有标记的数据集上,可以使用任何常见的损失函数,例如 平方损失,softmax loss, KL-loss. 本文的主要贡献就是提出一个在为标记数据集上的loss. 该函数具有如下的形式: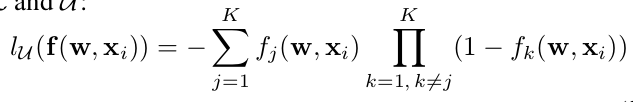
论文2
NIPS’16《Regularization With Stochastic Transformations and
Perturbations for Deep Semi-Supervised Learning》
这篇论文的核心思想
 本作品采用知识共享署名 2.5 中国大陆许可协议进行许可,欢迎转载,但转载请注明来自 Sunshine 并保持转载后文章内容的完整。本人保留所有版权相关权利。
本作品采用知识共享署名 2.5 中国大陆许可协议进行许可,欢迎转载,但转载请注明来自 Sunshine 并保持转载后文章内容的完整。本人保留所有版权相关权利。

